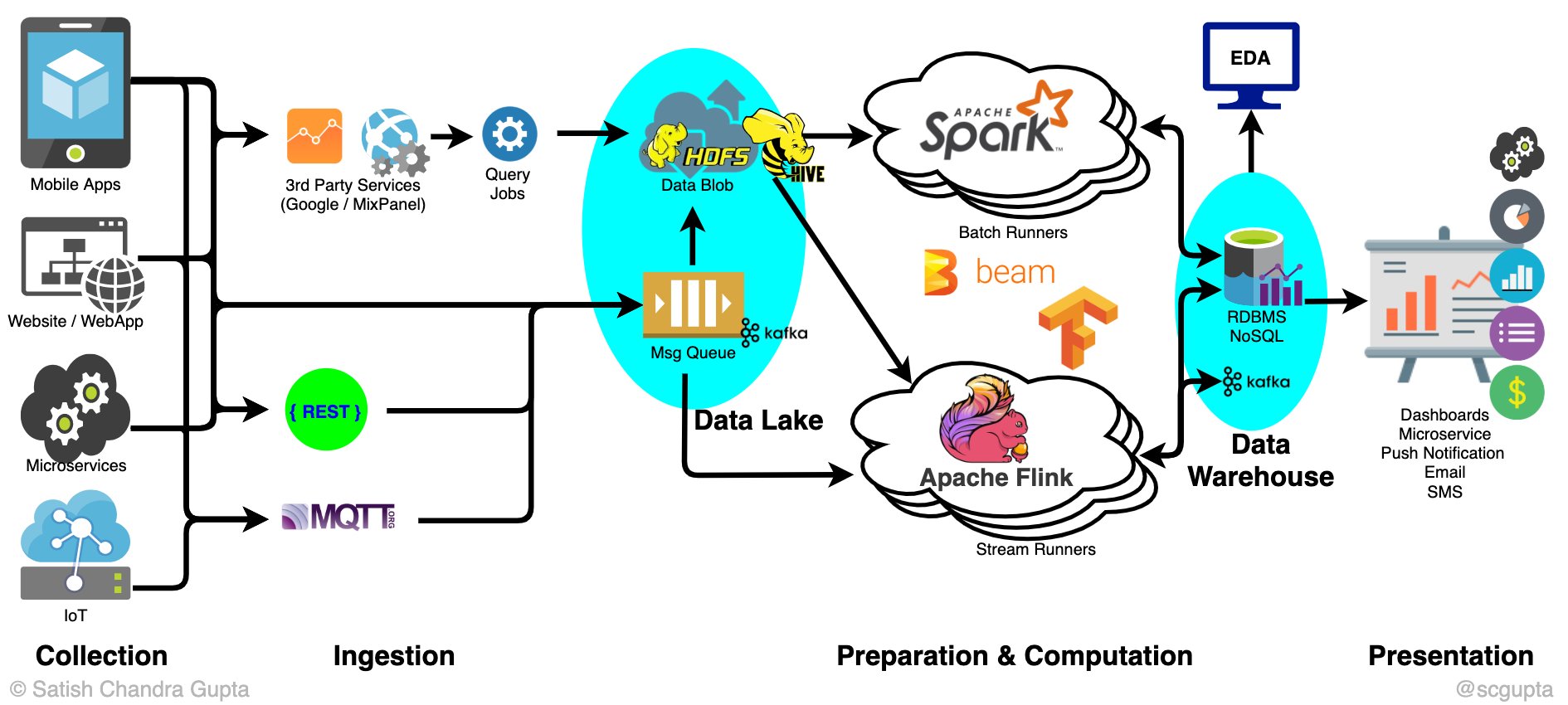
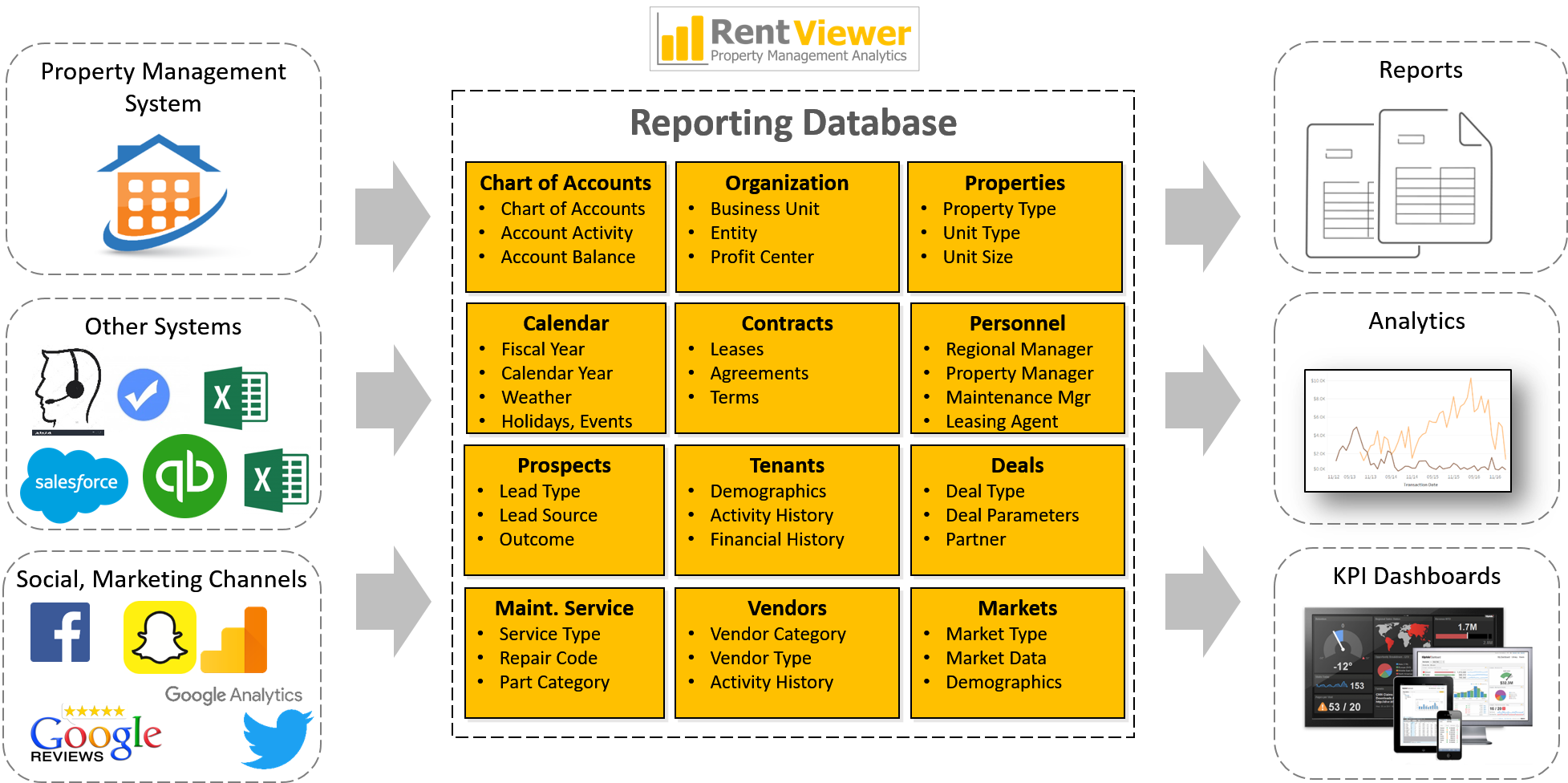
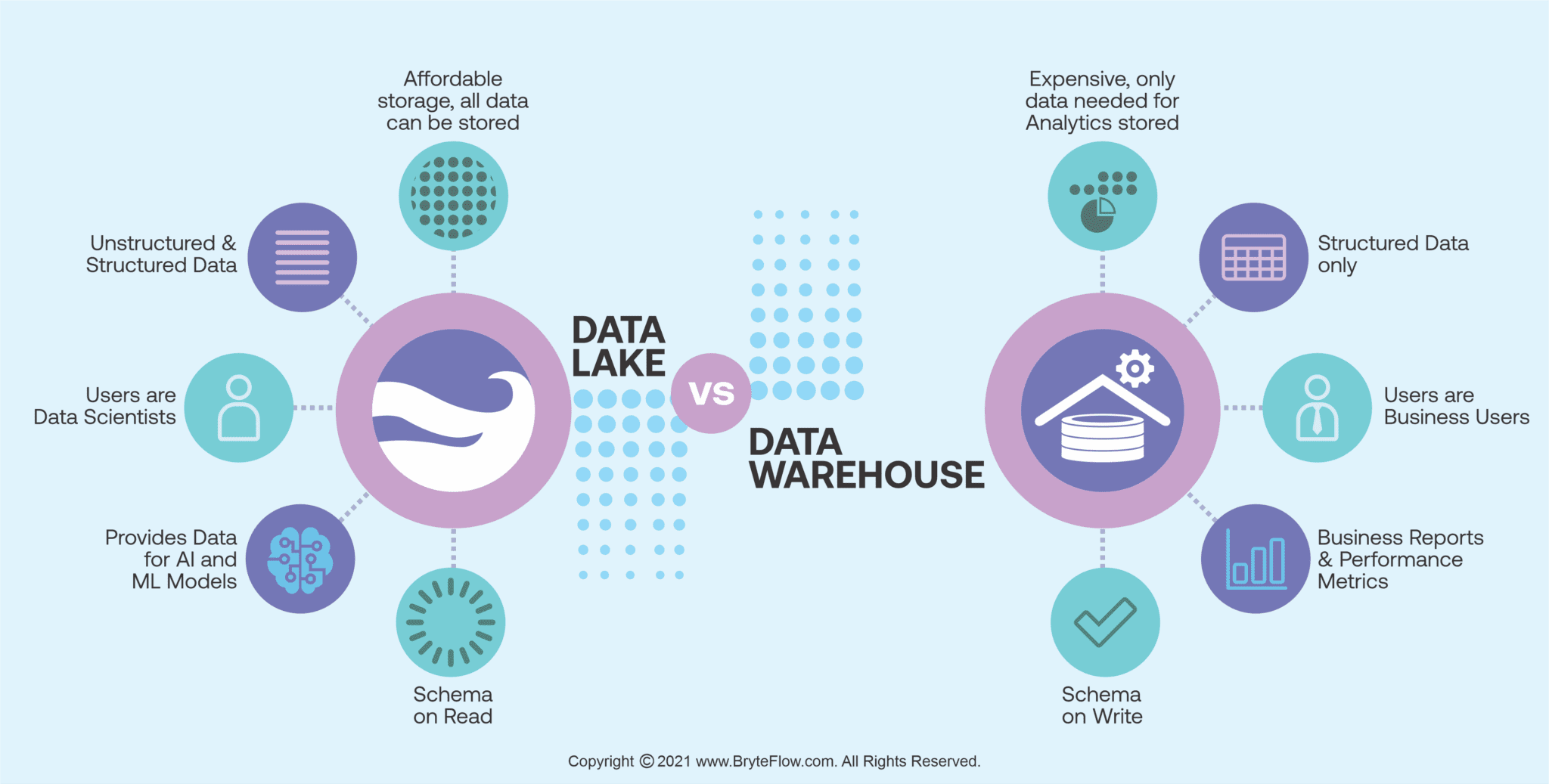
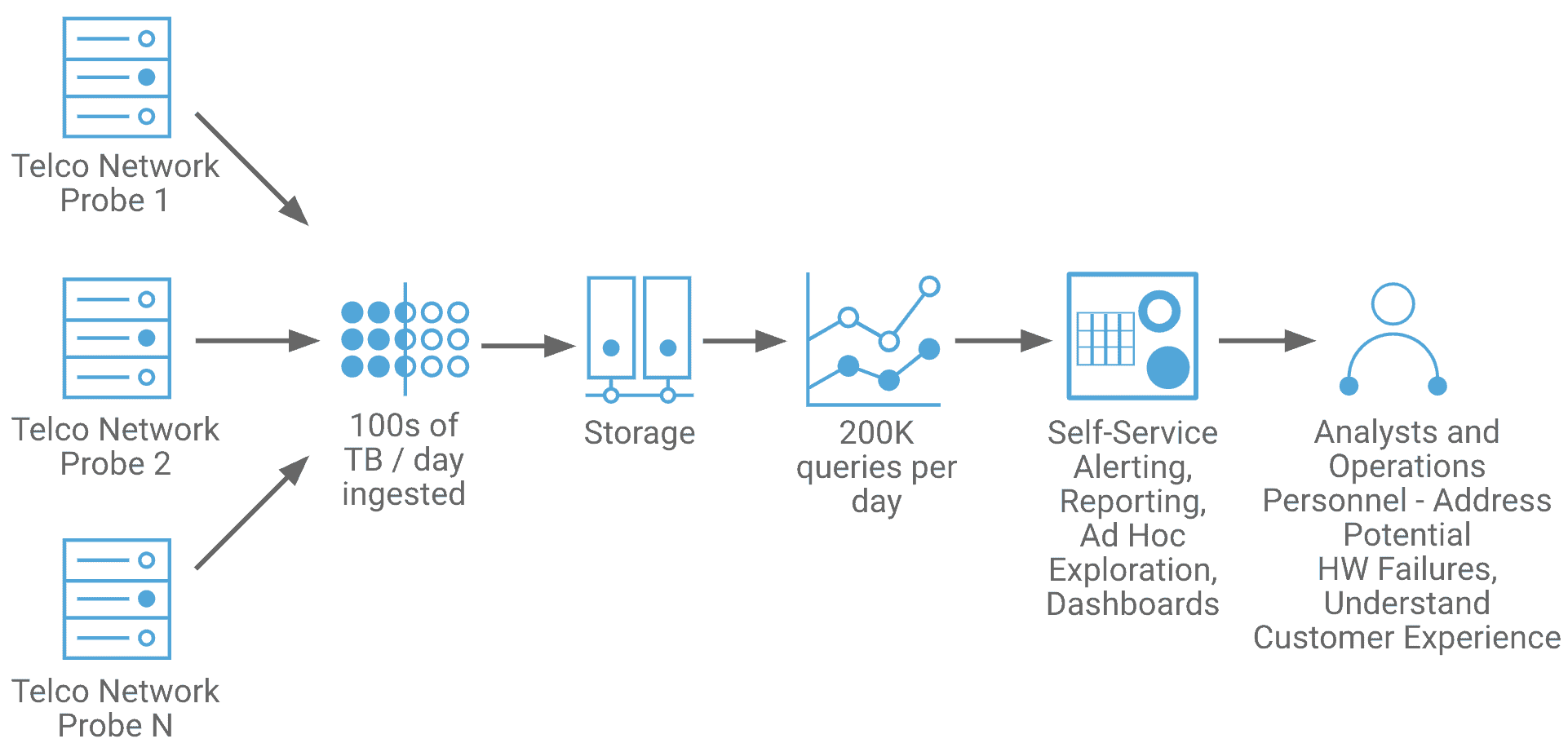
Data latency in data warehouse. When a Data Warehouse Can’t Keep it Real 2022-12-12
Data latency in data warehouse Rating:
5,4/10
883
reviews
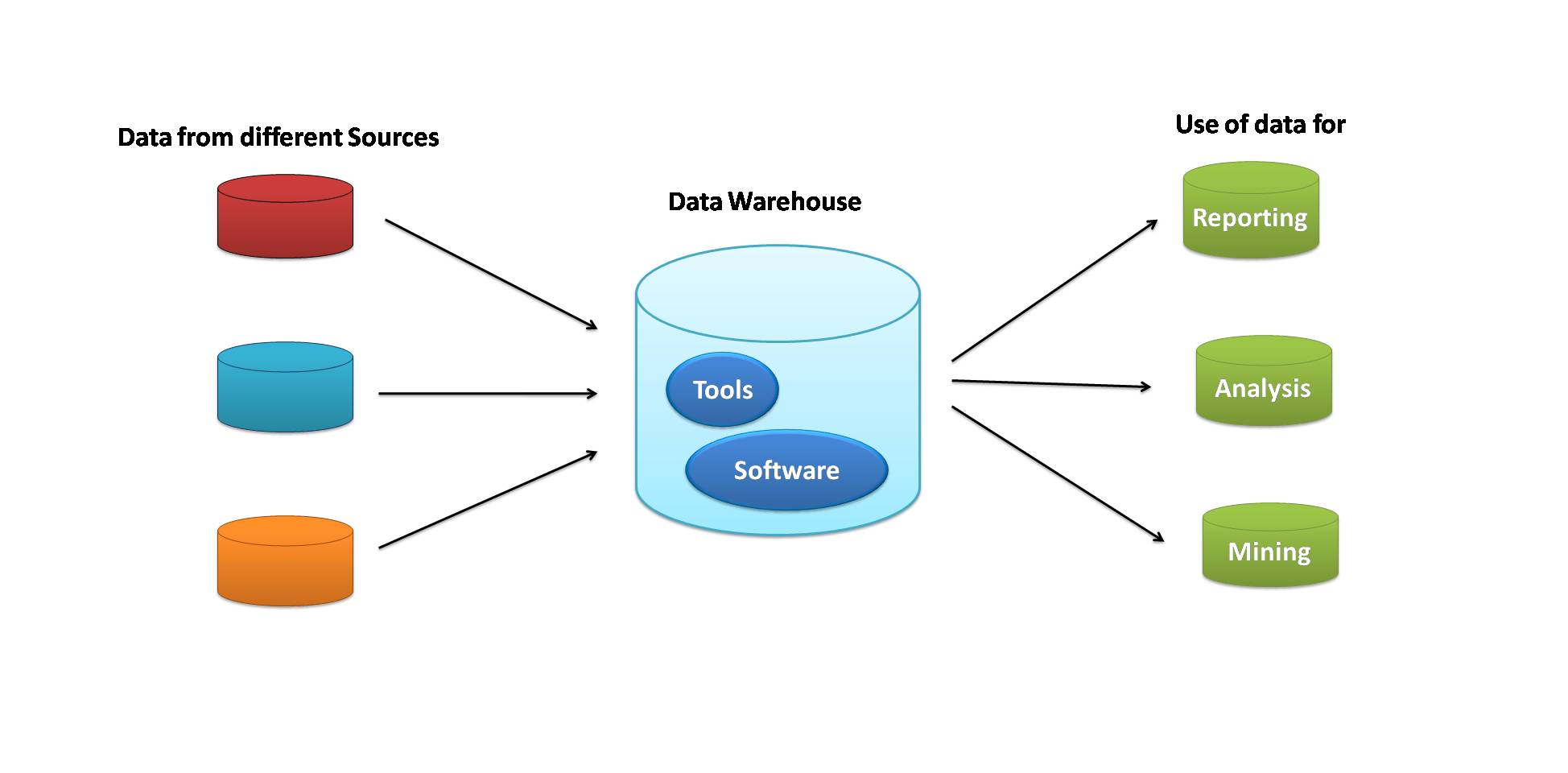
Data latency, or the time it takes for data to be transferred and processed, is a critical aspect of data warehousing. In a data warehouse, data latency can have a significant impact on the accuracy and usefulness of the data being analyzed.
There are several factors that can contribute to data latency in a data warehouse. One of the most common is the distance between the data source and the data warehouse. If the data source is located far from the data warehouse, it can take longer for the data to be transferred and processed. This is especially true if the data is being transferred over the internet, as internet speeds can vary significantly depending on the location and connection quality.
Another factor that can contribute to data latency is the volume of data being transferred. If a data warehouse is receiving a large volume of data, it can take longer for the data to be processed and made available for analysis. This is especially true if the data warehouse is not adequately equipped to handle the volume of data being transferred.
Finally, the complexity of the data being transferred can also impact data latency. If the data being transferred is highly complex, it may take longer for the data warehouse to process and make it available for analysis. This is because complex data often requires more advanced processing and analysis techniques, which can take longer to complete.
There are several ways to mitigate data latency in a data warehouse. One option is to optimize the data transfer process by using more efficient data transfer protocols or technologies. Another option is to invest in more powerful hardware and software to handle large volumes of data more efficiently. Additionally, data warehousing systems can be designed to handle complex data more efficiently, reducing the time it takes for the data to be processed and made available for analysis.
In conclusion, data latency is an important consideration in data warehousing, as it can have a significant impact on the accuracy and usefulness of the data being analyzed. By understanding the factors that contribute to data latency and taking steps to mitigate it, data warehousing systems can be optimized to provide more accurate and useful data in a timely manner.
Data Warehouse, Data Lake, Data Lakehouse: Understanding The Key Differences
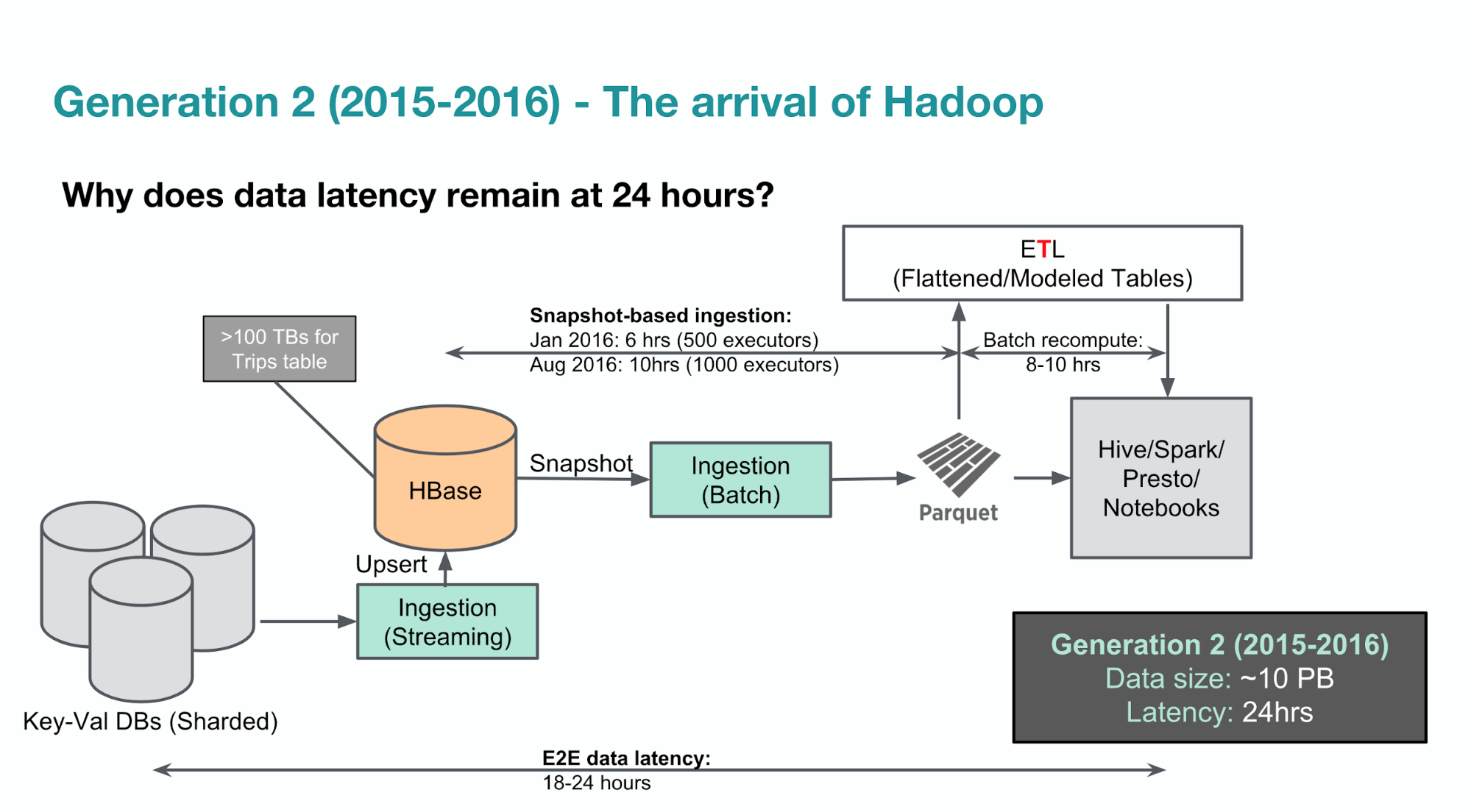
With snapshot-based ingestion of data, we ingest a fresh copy of the source data every 24 hours. This significantly lowered the operational cost of running a huge data warehouse while also directing users to Hadoop based query engines that were designed with their specific needs in mind. With their rigid structure, the queries and analysis that can be performed using data warehouse information is fixed. A data lakehouse brings together the strengths of the data lake and the data warehouse on one platform. A data lake, on the other hand, does not respect data like a data warehouse and a database.
Data Storage Explained: Data Lake vs Warehouse vs Database
Powerful data analytics does not depend on fast data replication. Other key considerations can be the importance of data consistency and timeliness for your company and the expertise of your data team. New data was only accessible to users once every 24 hours, which was too slow to make real-time decisions. This resulted in our Hadoop data lake becoming the centralized source-of-truth for all analytical Uber data. YSC session YSC cookie is set by Youtube and is used to track the views of embedded videos on Youtube pages.
Data Teams: Embrace the data warehouse. Turn it into a Composable CDP.
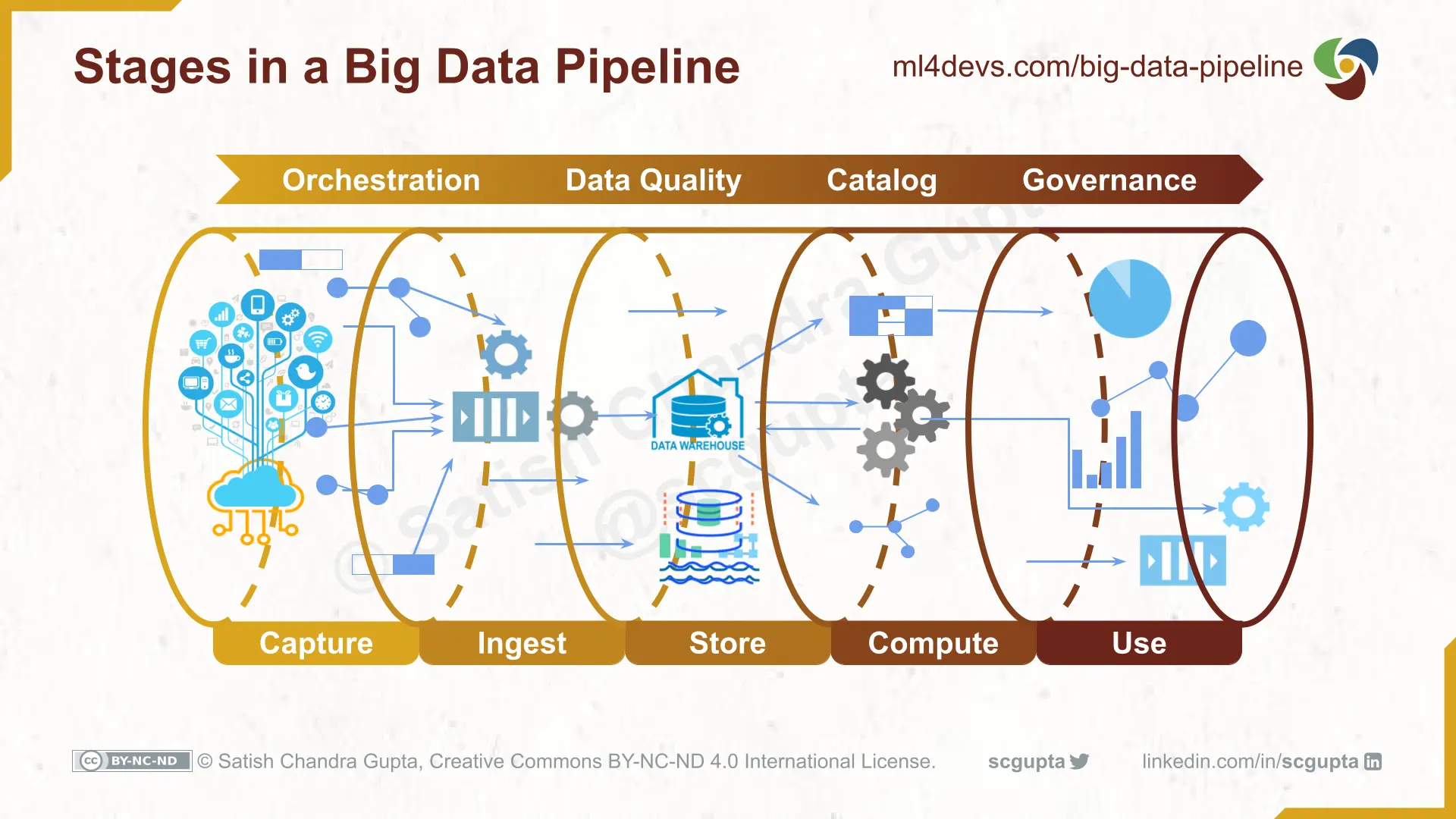
As a result, data lakes are highly scalable, which makes them ideal for larger organizations that collect a vast amount of data. Since every element in a composable CDP is modular, you can choose the best-in-class tools that fit the requirements at that time. Data lakes and data warehouses are very different, from the structure and processing all the way to who uses them and why. Incorporating technologies such as Parquet, Spark, and Hive, tens of petabytes of data was ingested, stored, and served. This option is commonly used when you have data that you need to pull in for a regularly scheduled report.
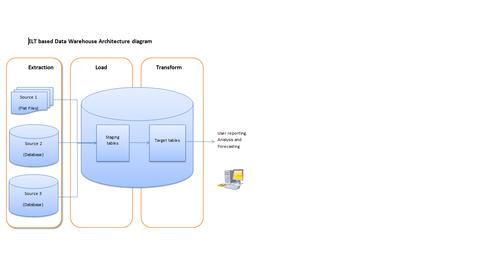
Simultaneously, the data lakehouse can still ingest unstructured, semi-structured or raw data from a variety of sources. In addition to this, data warehouse technology is a lot more established than the relatively new big data technologies. In other words, we ingest all updates at one time, once per day. Warehouses have built-in transformation capabilities, making this data preparation easy and quick to execute, especially at big data scale. Data lakes manage unstructured data. This alternative approach to a CDP is known by a few names: Composable CDP, unbundled CDP, headless CDP, etc. For example, if your sales team creates a quarterly report, then it doesn't need to have data updated every minute.
Do you have best practices that you create a new warehouse for each each team? Because when something goes sideways, you want to know exactly where you need to look to figure out what was. Houses the latest merged view of the upstream tables. However, we really encourage you to ask questions at any point during the session. But sometimes they want to hand off that last mile of deciding what to do with the different data points to the actual line of business team, like someone like a sales ops role or rev ops role marketing, tech role, something like that. And I think the biggest thing is you can have the hub and spoke model, but you still need to have the hub. The most important use is to provide the managers with relevant information for making better decisions.
As companies embrace machine learning and data science, data warehouses will become the most valuable tool in your data tool shed. Avoid this issue by summarizing and acting upon data before storing it in data lakes. These semantic checks in other words, Uber-specific data types allows us to add extra constraints on the actual data content beyond basic structural type checking. Is that a fair characterization? Large amounts of unstructured data are a reality for nearly all industries, and data lakes provide the means to quickly store that jumble of data. In particular where you care about joining that data together.
A data lake is a large storage repository that holds a huge amount of raw data in its original format until you need it. The final quip about that. Detect fraudulent financial activities Seconds matter when it comes to detecting and mitigating financial fraud. Vendors will often heavily discount their first year for this reason just ask any Segment customer. Long lag times are detrimental for retargeting and product recommendations based on what was recently added to a digital shopping cart. Today, however, the most common destination for this single source of truth is a dashboard.
Model and kind of the data warehouse or the Reverse ETL brain sort of reconcilers that to figure out if there is a change and if a signal that needs to be sent over. The lack of structure makes it difficult to obtain value from a data swamp. This allows the website owner to make parts of the website inaccessible, based on the user's log-in status. Scalability and reliability As part of our effort to improve the scalability and reliability of our platform, we identified several issues related to possible edge cases. Better data governance Rather than an off-the-shelf CDP managing all of your customer data, the composable CDP is built on top of your data warehouse so you get to leverage all your existing data governance, security, and observability protocols for managing your customer data. And a lot of other things follow in the organization. The simplest approach to vectorized decoding, and the one often initially implemented in Parquet decoders, is to decode an entire RowGroup or ColumnChunk at a time.
How do you go about understanding, all the various integrations, all the various syncs, what sort of data catalog for Reverse ETL. I think Amy Chen wrote an article about that a couple of years back. In fact, Hudi allows ETL jobs to fetch only the changed data from the source table. So we go with that. Provides a holistic view on the entire Hadoop table at that point in time.